Java 中的高效计数器
原文地址:http://www.programcreek.com/2009/02/a-simple-treeset-example/
您可能经常需要一个计数器来统计数据库或文本文件中某些内容(例如单词)的频率。我们一般通 Java HashMap 来实现计数器,本文比较了不同的实现方法,最后,选出一个最高效的。
1. 粗暴的计数器
String s = "one two three two three three";
String[] sArr = s.split(" ");
//naive approach
HashMap<String, Integer> counter = new HashMap<String, Integer>();
for (String a : sArr) {
if (counter.containsKey(a)) {
int oldValue = counter.get(a);
counter.put(a, oldValue + 1);
} else {
counter.put(a, 1);
}
}
在每次循环中,检查键是否存在。如果存在,将 oldValue 加1,如果不是,将其设置为1。这种方法是最简单直接的,但它不是最有效的。 该方法效率较低的原因:
- 当键存在时,
containsKey(),get()方法将被调用两次,这意味需要搜索 map 两次 - 由于 Integer 是不可变的,所以每次循环都会创建一个新的 oldValue
2. 优化后的计数器
我们需要一个可变整数,以避免创建许多 Integer 对象,可变整数类可以定义成:
class MutableInteger {
private int val;
public MutableInteger(int val) {
this.val = val;
}
public int get() {
return val;
}
public void set(int val) {
this.val = val;
}
//used to print value convinently
public String toString(){
return Integer.toString(val);
}
}
然后我们优化一下计数器:
HashMap<String, MutableInteger> newCounter = new HashMap<String, MutableInteger>();
for (String a : sArr) {
if (newCounter.containsKey(a)) {
MutableInteger oldValue = newCounter.get(a);
oldValue.set(oldValue.get() + 1);
} else {
newCounter.put(a, new MutableInteger(1));
}
}
这似乎是最好的方式了,因为它不再需要创建许多整数对象。但是,如果键存在,则每次循环中的搜索仍然是两次。
3. 高效的计数器
HashMap.put(key, value) 方法会返回键的当前值,这对我们很有用,因为我们去更新 oldValue 时不需要在搜索两次了。
HashMap<String, MutableInteger> efficientCounter = new HashMap<String, MutableInteger>();
for (String a : sArr) {
MutableInteger initValue = new MutableInteger(1);
MutableInteger oldValue = efficientCounter.put(a, initValue);
if(oldValue != null){
initValue.set(oldValue.get() + 1);
}
}
4. 性能差异
为了测试以上三种不同方法的性能,我们使用以下代码,测试100万次,结果如下:
Naive Approach : 222796000
Better Approach: 117283000
Efficient Approach: 96374000
测试结果的差异是很明显的,这说明创建对象的代价是很大的!
String s = "one two three two three three";
String[] sArr = s.split(" ");
long startTime = 0;
long endTime = 0;
long duration = 0;
// naive approach
startTime = System.nanoTime();
HashMap<String, Integer> counter = new HashMap<String, Integer>();
for (int i = 0; i < 1000000; i++)
for (String a : sArr) {
if (counter.containsKey(a)) {
int oldValue = counter.get(a);
counter.put(a, oldValue + 1);
} else {
counter.put(a, 1);
}
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("Naive Approach : " + duration);
// better approach
startTime = System.nanoTime();
HashMap<String, MutableInteger> newCounter = new HashMap<String, MutableInteger>();
for (int i = 0; i < 1000000; i++)
for (String a : sArr) {
if (newCounter.containsKey(a)) {
MutableInteger oldValue = newCounter.get(a);
oldValue.set(oldValue.get() + 1);
} else {
newCounter.put(a, new MutableInteger(1));
}
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("Better Approach: " + duration);
// efficient approach
startTime = System.nanoTime();
HashMap<String, MutableInteger> efficientCounter = new HashMap<String, MutableInteger>();
for (int i = 0; i < 1000000; i++)
for (String a : sArr) {
MutableInteger initValue = new MutableInteger(1);
MutableInteger oldValue = efficientCounter.put(a, initValue);
if (oldValue != null) {
initValue.set(oldValue.get() + 1);
}
}
endTime = System.nanoTime();
duration = endTime - startTime;
System.out.println("Efficient Approach: " + duration);
当你使用计数器时,可能还需要一个按值排序 Map 的功能,您可以查看 常用的 HashMap 方法。
5. Keith 的解决方案
新增了几个测试: 1)重构 "Better Approach",只调用 get 而不是 containsKey。通常,您希望的元素已在 HashMap 中,这样就可以让两次搜索减少到一次。 2)添加了一个与 AtomicInteger 相关的测试,这是 michal 提到的。 3)与单例整型数组相比,据说会占用较少的内存 http://amzn.com/0748614079
我运行了这个测试程序 3 次,取最小值并从其他程序中去除差异。请注意,你不能在程序中执行此操作,否则结果将受到很大影响,因为有可能引起垃圾回收(GC)。
Naive: 201716122
Better Approach: 112259166
Efficient Approach: 93066471
Better Approach (without containsKey): 69578496
Better Approach (without containsKey, with AtomicInteger): 94313287
Better Approach (without containsKey, with int[]): 65877234
Better Approach (without containsKey):
HashMap<String, MutableInteger> efficientCounter2 = new HashMap<String, MutableInteger>();
for (int i = 0; i < NUM_ITERATIONS; i++) {
for (String a : sArr) {
MutableInteger value = efficientCounter2.get(a);
if (value != null) {
value.set(value.get() + 1);
} else {
efficientCounter2.put(a, new MutableInteger(1));
}
}
}
Better Approach (without containsKey, with AtomicInteger):
HashMap<String, AtomicInteger> atomicCounter = new HashMap<String, AtomicInteger>();
for (int i = 0; i < NUM_ITERATIONS; i++) {
for (String a : sArr) {
AtomicInteger value = atomicCounter.get(a);
if (value != null) {
value.incrementAndGet();
} else {
atomicCounter.put(a, new AtomicInteger(1));
}
}
}
Better Approach (without containsKey, with int[]):
HashMap<String, int[]> intCounter = new HashMap<String, int[]>();
for (int i = 0; i < NUM_ITERATIONS; i++) {
for (String a : sArr) {
int[] valueWrapper = intCounter.get(a);
if (valueWrapper == null) {
intCounter.put(a, new int[] { 1 });
} else {
valueWrapper[0]++;
}
}
}
Guava 的 MultiSet 可能还更快!
6. 结论
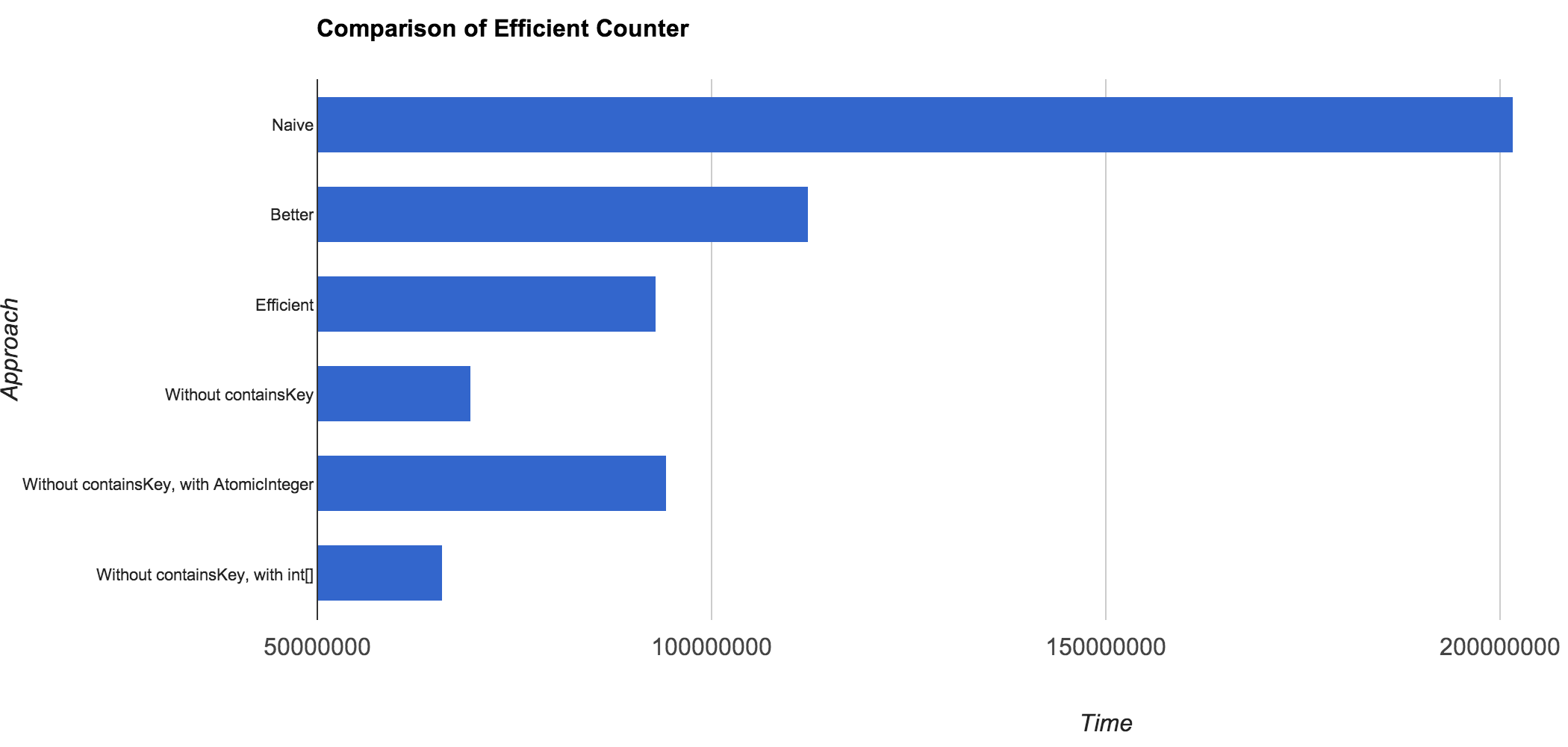
很显然,获胜者是最后使用整型数组那个方式。
参考阅读: